Seow Lim, Darin Clemmer, Gerald Kuntsman, and Swanand Mhalagi contributed to the development of this article.
Artificial Intelligence (AI) has been a hot topic, especially since the introduction of end-user applications, such as ChatGPT. Benchmarking performance is the best way to determine which hardware configurations are most efficient for different AI use cases. Benchmarking performance is the best way to determine the most efficient hardware for different AI use cases.
Benchmark Methodology
Three AI programs were selected for benchmarking based on their distinct AI use cases – ResNet50 (Image classification) and SSD-Resnet34 (Image Object detection), BERT (Natural Language Processing), and DIEN Recommendation models.
The applications were run on different precisions, such as FP32 (floating-point 32), INT8 (integer 8), and BF16 (bfloat16) precision, which are data types used to represent real numbers with higher precision, integers with lower precision, and intermediate precision, respectively.
The choice of precision comes down to the trade-off between computational accuracy and computational efficiency. FP32 offers higher accuracy, but it requires more computing power and longer computation time. This may not be feasible for some applications. INT8 has a faster computation time and uses less computing resources. This makes it perfect for real-time applications that require speed and efficiency. BF16 precision is specific to SPR, in addition to FP32 and INT8 available on ICX, and has newer instructions (AMX) that provide added benefits for inferencing.
SPR has BF16 precision in addition to FP32 and INT8 available on ICX. SPR also has a newer set of instructions (AMX) which provide added benefit for inferencing.
Benchmarked AI applications
List of AI Program Modes for Testing
- For real-time performance, low latency and high-speed processing are usually required. Hardware must be capable of processing data quickly and responding to inputs in real-time. In the case of ImageNet for example, the AI system needs to be able process/infer the images in real time, similar to steaming. Therefore, real-time AI applications often require high-end hardware, such as GPUs or specialized AI chips, with low-latency memory and high-speed I/O interfaces.
- Maximum throughput requires hardware that can process large amounts of data efficiently. This typically involves parallel processing capabilities and high memory bandwidth to handle large datasets.
List of AI Program Hardware Acceleration
- AMX (Advanced Matrix Extensions) is a set of instructions that are part of Intel’s 4th Gen Xeon architecture. AMX was designed to speed up the processing of matrix operations, which are often used in neural network layers such as convolutional ones. AMX can perform matrix multiplication and accumulation operations with low power consumption and high efficiency.
- VNNI (Vector Neural Network Instructions) is a set of instructions that are part of the Intel AVX-512 instruction set architecture. VNNI was designed to speed up the processing of CNNs by accelerating inner product operations. VNNI can perform multiple vector dot-product operations in a single instruction, which can improve the performance of neural network computations.
List of Optimization Libraries
- FP32 (floating-point 32): Data type used to represent real numbers with higher precision, but it requires more memory and computation compared to INT8. Machine learning models using FP32 are more accurate, but they require more computing power and longer computation time. This can result in longer training and inference times, which may not be practical for certain applications.
- INT8 with Intel Neural Compressor (data type used to represent integers with lower precision, but it requires less memory and computation compared to FP32. INT8-based machine learning models can be deployed in real-time scenarios where speed and efficiency is critical. They require less computing resources and faster computations. However, the lower precision of INT8 can result in reduced model accuracy, which may not be acceptable for certain applications)
- BF16 precision, this type of precision is specific to SPR in addition to FP32 and INT8 available on ICX. SPR also has a newer set of instructions (AMX) which provide added benefit for inferencing.
Benchmarking Intel CPUs for AI
Intel has been actively contributing to the development of artificial intelligence (AI) technology. Most notably, Intel CPUs have been used for facilitating machine learning, natural language processing (NLP), and deep learning.
To further improve the performance of their line-up, Intel has released CPUs specifically designed for AI, such as Intel Xeon Scalable Processors and the Intel Xeon Phi Coprocessor.
The following are the servers used in benchmarking:
3rd Gen Xeon SP System Configuration
- phoenixNAP Bare Metal Cloud Instance Type: d2.c5.medium
- Dual Socket 8352Y 3rd Gen Xeon SP
- 256GB DDR4 2933MT/s
- 2x INTEL 2TB P4510 NVMe
- Operating System: CentOS Stream 8
- Kernel: 6.2.2-1.el8.elrepo.x86_64
4th Gen Xeon SP System Configuration
- phoenixNAP Bare Metal Cloud Instance Type: d3.m6.xlarge
- Dual Socket 8452Y 4th Gen Xeon SP
- 256GB DDR5 4800MT/s
- 2x INTEL 2TB P4510 NVMe
- Operating System: CentOS Stream 8
- Kernel: 6.2.2-1.el8.elrepo.x86_64
NLP programs involve processing large amounts of unstructured textual data, requiring high processing power and memory. Hardware with high-end CPUs, such as the Intel Xeon Scalable processors, can provide the necessary processing power to handle complex NLP tasks.
Recommendation engines require more memory and storage than processing power, as they involve accessing large datasets to make recommendations. Hardware with large memory capacity and storage, such as Intel Optane DC Persistent Memory, can provide the necessary resources to handle recommendation engine tasks efficiently.
In contrast, image recognition AI programs require high computational power and processing speed to process large amounts of image data. Hardware with high-performance GPUs, such as the Intel Xe GPU, provides the required processing power to handle complex image recognition tasks.
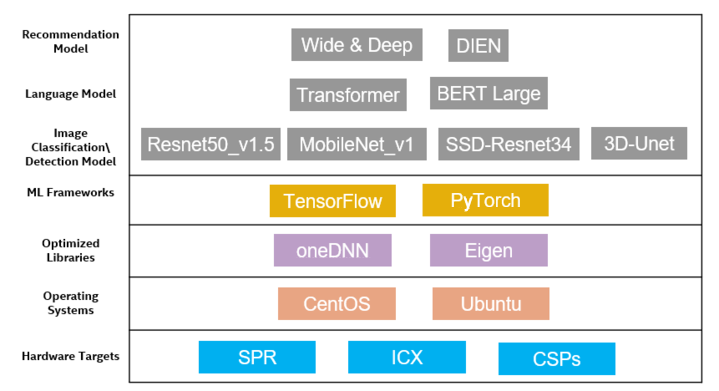
AI Inferencing Performance on Intel Hardware/Software Stack
The method used to evaluate AI inferencing performance on the benchmarked Intel hardware/software stack involved the following steps:
- Identify the AI program to be benchmarked and the specific hardware configurations to be tested.
- Select a standard benchmarking tool, such as TensorFlow or PyTorch, to evaluate the AI program’s performance on each hardware configuration.
- Install and configure the benchmarking tool on each hardware configuration.
- Run the benchmarking tool and record the results for each hardware configuration, including metrics such as processing speed, memory usage, and accuracy.
- Compare the results to identify the most efficient and effective hardware configuration for the specific AI program.
- Repeat the benchmarking process with different benchmarking tools or configurations to validate the results, if necessary.
- Following this method, organizations can determine the most optimal hardware configuration for their AI applications, maximizing performance and minimizing costs. Benchmarking AI applications on different Intel CPUs can be a crucial step to support complex data-driven decision making processes. Each test can have a variation of up to 5%. To ensure consistent results across all test cases, each scenario was run up 4 times.
BF32 can be skipped as very few models support that precision as of now.
Methodology and Results
The methodology used for benchmarking involves measuring the overall throughput of various models. For the Bert_large, Dien, and Restnet50 models, the throughput was calculated by determining the number of input sequences or examples that could be processed in a certain time period. The benchmark tests compared the performance difference from the following variables: CPU, instruction set (VNNI VS AMX), use case (max throughput vs. real time), and precision (FP32, float8 and Int8).
The results of our benchmarking are shown in the table below:
Figure 2: Performance of Gen3 (8352y) vs Gen 4 (8452y) Xeon Scalable CPUs in real time
Figure 3: Performance of Gen3 (8352y) vs Gen 4 (8452y) Xeon Scalable CPUs max throughput
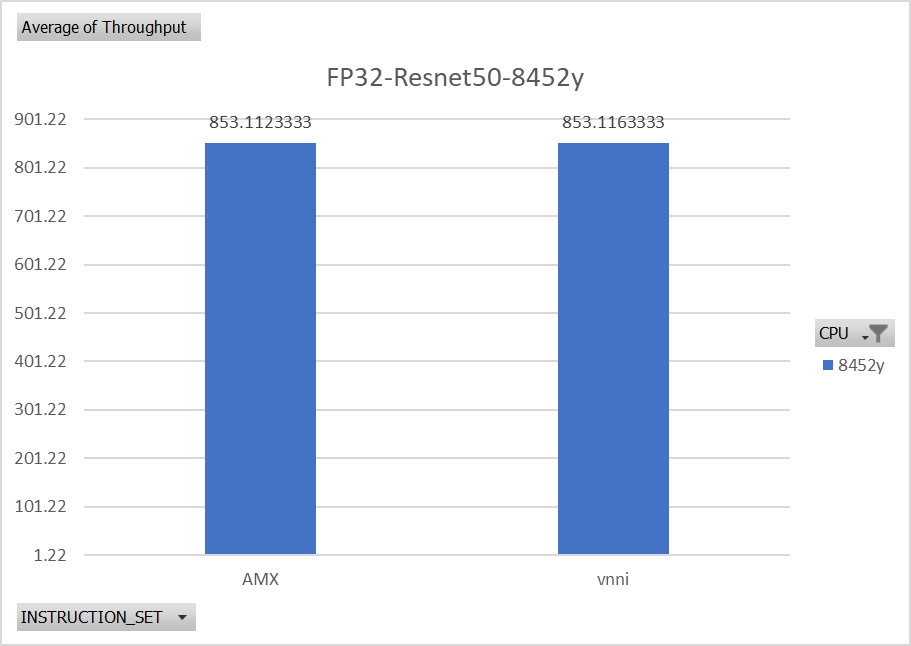
Figure 2 and Figure 3 compare the performance between Gen 3 and Gen 4 Intel Xeon Scalable CPUs under the same criteria (FP32 and VVNI). The results of our benchmarking show that the performance of Gen 3 (8352y) vs Gen 4 (8452y) Xeon Scalable CPUs in real time is a significant increase. Figure 2 and Figure 3 compare the performance of Gen 3 (8352y), compared to Gen 4 Xeon Scalable CPUs in max throughput. The use of higher computational power will result in faster processing of user behaviour sequences and item interaction, which can then lead to more accurate and timely recommendation. While the benefits of higher computational power are also evident in models like ImageNet and BERT, the performance increase is the most significant in recommendation models like DIEN.
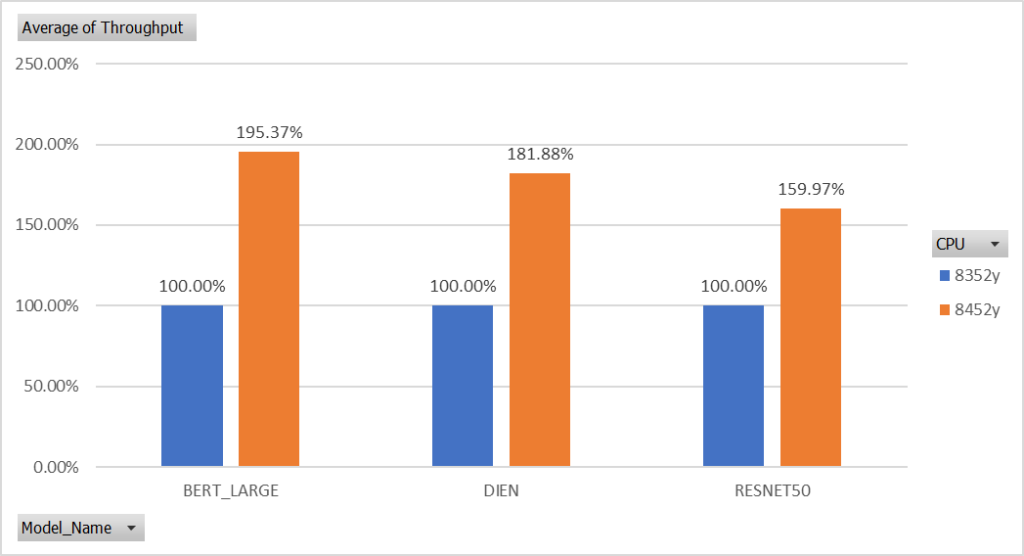
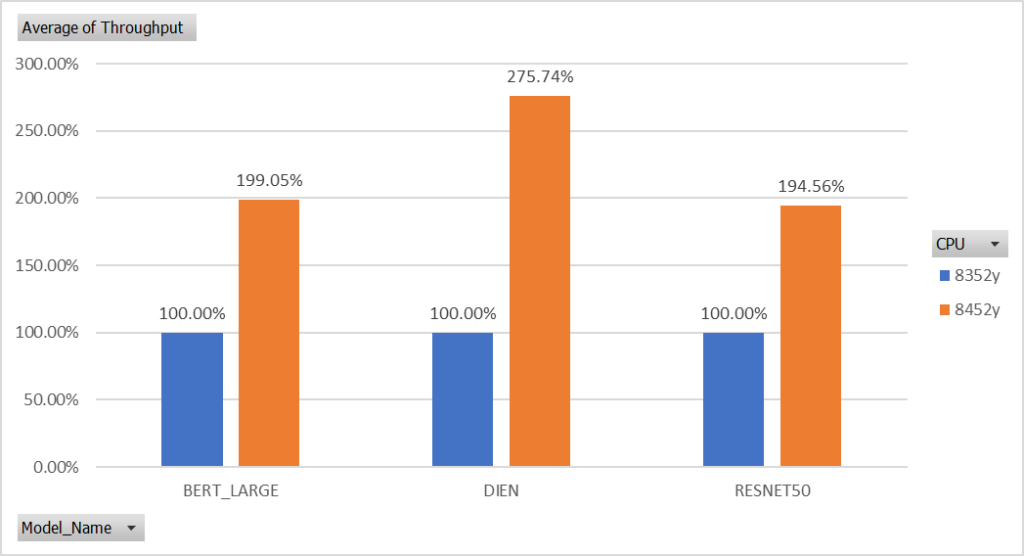
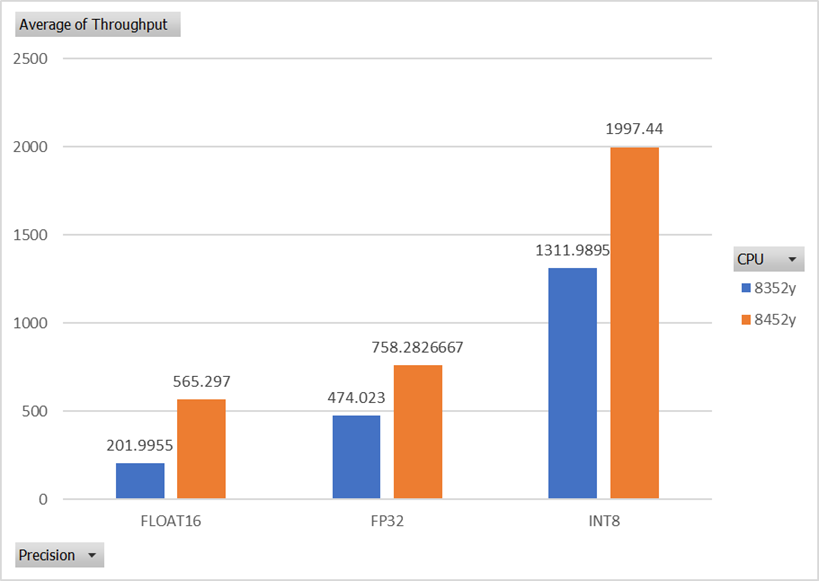
Figure 5: Bert_LARGE Xeon Scalable CPUs throughput performance comparison using different precisions
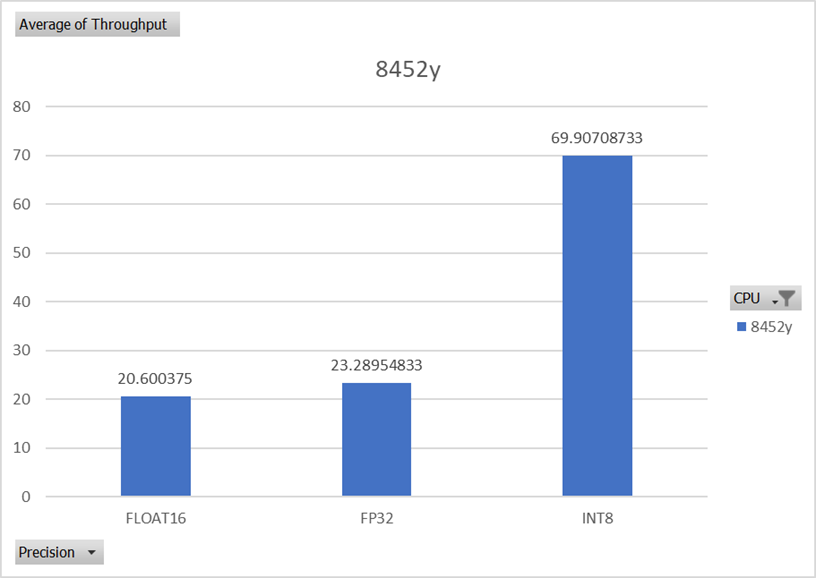
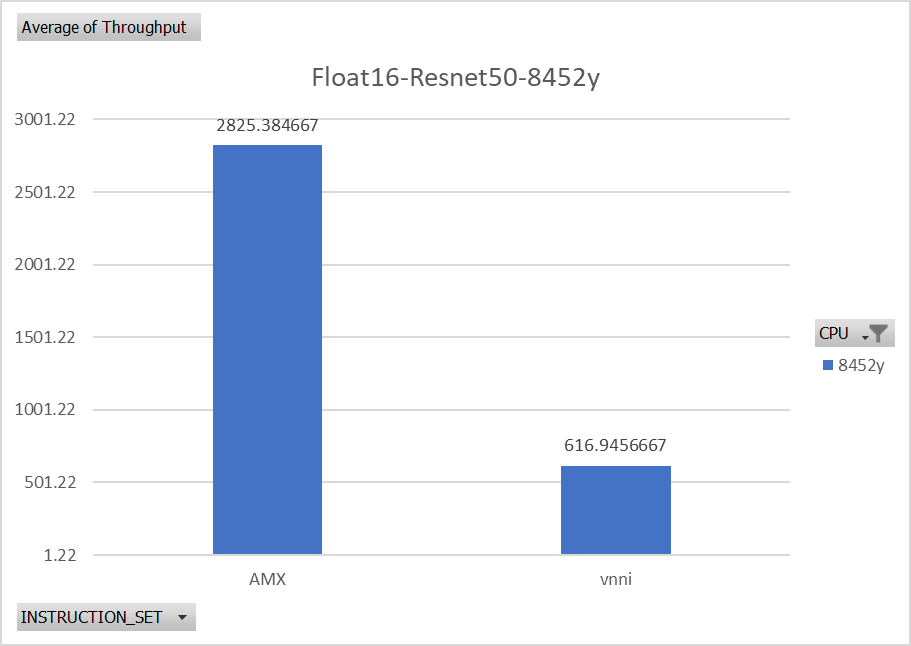
Figure 4 and Figure 5 analyze the impact of different data precisions on the performance of various models. As shown by ResNet50’s image classification model, using INT8 (8 bit integer) inference results in significantly better performance than FP32 (32 bit floating-point). This model also showed a performance boost of 3.5x. These results demonstrate that the INT8 data type can provide better performance than FP32 due to its ability to leverage hardware accelerators and more efficiently utilize the CPU.
Figure 6: ImageNet throughput performance comparison on different instruction set for ImageNet model using FP32
Conclusion
In this research, we identified that the choice of CPU plays a crucial role in achieving optimal performance for AI applications. This is especially true for recommendation engines with maximum throughput mode. This is especially true in the case of recommendation engines with maximal throughput mode,
About The Author
By omurix
XIII. Unidentified Society